Ansible - Inventories 2/3
Ansible can be used to configure and orchestrate a bunch of machines. As explained in a previous article, it is quite easy to write and maintain a simple inventory. Now let's add some variables to it, so we can maintain our infrastructure settings in a central place.


Ansible can be used to configure and orchestrate a bunch of machines. As explained in a previous article, it is quite easy to write and maintain a simple inventory. Now let's add some variables to it, so we can maintain our infrastructure settings in a central place.
In this article, we will have a look at Ansible Inventories and the meaning of variables in it.
Prerequisites
First things first: Starting with this article, if you never heard of Ansible, may be hard. If you are completely new to Ansible, I strongly suggest starting with "Ansible - Getting Started" and "Ansible - Playbook".
We will start with the same setup as described in the previous article. Here is the graphic again, which can be reproduced on your own or by using a Vagrantfile.
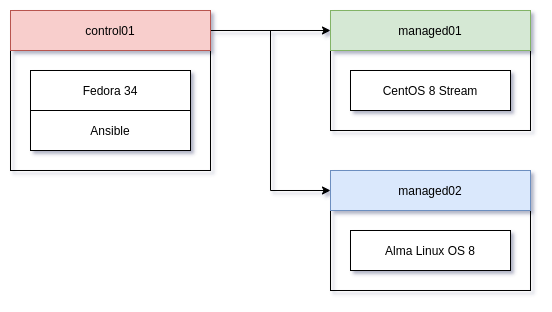
If you skipped the article, here is a brief summary of the needed files and preparation. First, create a directory for your project and copy the below content to the proper files.
# Create project directory
$ mkdir ansible-inventories-2
# Changee to directory
$ cd ansible-inventories-2Create an Ansible inventory like this:
---
# inventories/practice/inventory.yml
all:
children:
control:
hosts:
control01:
ansible_ssh_host: 192.168.122.100
managed:
hosts:
managed01:
ansible_ssh_host: 192.168.122.101
managed02:
ansible_ssh_host: 192.168.122.102Please ensure that you adjusted the IP addresses to your environment, if needed. Lastly, we will need a simple playbook like this one:
---
# playbook.yml
- name: "Target all hosts"
hosts: "all"
tasks:
- name: "Install Git"
ansible.builtin.package:
name: "git"
state: "present"
become: trueFor a more detailed explanation, I recommend having another look at "Ansible - Inventories 1/3".
Demand for variables
Let's assume you are having an information, like the hostname, that is needed in different places. Writing the hostname over and over again is not very practical. Such a scenario can be covered with Inventory variables.
If you maintain different environments like Dev and Prod, you will very likely have similar settings in both and others that are different. But the playbook will be very likely the same. This can also be covered with variables.
Lastly, you may have a situation, where you want to make your playbooks readable, loop over a list of items or adjust package names according to the distribution. This is also covered with variables.
Let's see how these scenarios can be covered in our demo setup and how you can organize and store your variables.
Playbook Vars
The easiest way to use variables is - store them directly in your playbook. This can be done for testing purposes or if you just have a bunch of minimal settings, you want to apply.
Let's assume, we want to change the playbook, so it does install Git and a bunch of other useful tools on the nodes.
You need to edit the playbook.yml as described below.
---
# playbook.yml
- name: "Target all hosts"
hosts: "all"
vars:
tools:
- "tmux"
- "git"
- "htop"
- "nmap"
tasks:
- name: "Install Tools"
ansible.builtin.package:
name: "{{ tools }}"
state: "present"
become: trueThe above code will use the defined variable tools and install the list of packages. You only need to ensure, that the variable is properly defined, and you can use it in your playbook with the curly bracket syntax "{{ tools }}". In fact, this is Jinja2 and Ansible is using Jinja2 Template language all over the place.
The tricky part is now: What if you want to use the same Install Tools task for all the nodes, but use different packages for different nodes. For example, you want to have nmap and git only on the nodes in the group control, but tmux and htop on all of them.
This is where inventory variables kick in, and I will demonstrate this in the next section.
Inventory File Vars
You can define variables directly in your inventory file. This is very useful, if you don't have a ton of variables. Let's use the example from above. This time, we want to ensure that the group "control" gets a set of tools, but the group "managed" is getting a different set.
First, we need to remove the variables from the playbook, so it looks like the below snippet.
---
# playbook.yml
- name: "Target all hosts"
hosts: "all"
tasks:
- name: "Install Tools"
ansible.builtin.package:
name: "{{ tools }}"
state: "present"
become: trueRunning this playbook will fail, since the variable "tools" is undefined. Let's adjust the inventory to fix this.
---
# inventories/practice/inventory.yml
all:
children:
control:
vars:
tools:
- "git"
- "nmap"
- "tmux"
- "htop"
hosts:
control01:
ansible_ssh_host: 192.168.122.100
managed:
vars:
tools:
- "tmux"
- "htop"
hosts:
managed01:
ansible_ssh_host: 192.168.122.101
managed02:
ansible_ssh_host: 192.168.122.102Running the above playbook will install git, tmux, htop and nmap on all nodes in the group "control" and tmux and htop in the group "managed".
# Execute playbook with specific inventory.yml
$ ansible-playbook -k -K -i inventories/practice/inventory.yml playbook.ymlThis scenario can be applied to all kinds of things. You can have different NTP servers or DNS servers per group. You can also have different users and passwords or security policies for your firewall.
But maintaining hundreds of variables next to the hosts and groups will make the inventory very cluttered and hard to read.
Group Vars and Host Vars
Another abstraction layer can be added with Group Vars and Host Vars. This will allow to have your variables in separate files, next to your inventory. Group Vars can be used to allocate variables to a group and Host Vars for single hosts.
Let's see how this works and refactor our inventory accordingly. For now, the directory structure we are having is looking like this:
# Show the directory tree
$ tree
.
├── inventories
│ └── practice
│ └── inventory.yml
└── playbook.yml
Now, let's add some directories and files to it, to make use of Group Vars. In general, this can be done in two ways. I will show both and explain why I prefer one over the other.
group.yml and host.yml
Most examples you will find on the web are using a structure like the below.
# Show the directory tree
$ tree
.
├── inventories
│ └── practice
│ ├── group_vars
│ │ ├── control.yml
│ │ └── managed.yml
│ ├── host_vars
│ │ └── managed01.yml
│ └── inventory.yml
└── playbook.yml
As you can see, you will have 2 new directories (group_vars and host_vars) next to the inventory file, and you can create YAML files with the "host name" or "group name" as defined in your inventory. All the files are optional and will only be used, if they exist. You can also add a file "all.yml" to define variables for all hosts and groups.
After refactoring the inventory, we will end up with these files.
---
# playbook.yml
- name: "Target all hosts"
hosts: "all"
tasks:
- name: "Install Tools"
ansible.builtin.package:
name: "{{ tools }}"
state: "present"
become: true---
# inventories/practice/inventory.yml
all:
children:
control:
hosts:
control01:
ansible_ssh_host: 192.168.122.100
managed:
hosts:
managed01:
ansible_ssh_host: 192.168.122.101
managed02:
ansible_ssh_host: 192.168.122.102---
# inventories/practice/group_vars/control.yml
tools:
- "git"
- "nmap"
- "tmux"
- "htop"---
# inventories/practice/group_vars/managed.yml
tools:
- "tmux"
- "htop"Executing the playbook will work exactly the same as in the previous example (that's why it is called refactoring ^^).
# Execute playbook with specific inventory.yml
$ ansible-playbook -k -K -i inventories/practice/inventory.yml playbook.ymlgroup/vars.yml and host/vars.yml
You can also use a slightly different layout for more flexibility and control over the variables that are used. If you create a directory, named like the group or host, Ansible will read all files in this directory.
This way, you can have different variable files for general settings, database settings, server variables, etc. It's also beneficial, if you intend to use Ansible Vault (will be addressed in a future article).
For our example, we can keep it quite simple, as outlined below.
# Show the directory tree
$ tree
.
├── inventories
│ └── practice
│ ├── group_vars
│ │ ├── control
│ │ │ └── vars.yml
│ │ └── managed
│ │ └── vars.yml
│ ├── host_vars
│ └── inventory.yml
└── playbook.yml
The content of the files will be exactly the same as in the previous example. Running the playbook will also result in the same experience as before.
I prefer this layout over the others, since you are getting much more flexibility and options. It can be hard to read for beginners, though.
Multiple environments
Now, that we can have a more or less complex inventory for one landscape or scope, let's talk about multiple environments. For example, you want to have a dev, stage and prod environment or different datacenter sites and these will need to have different variables and inventories.
For me, a schema like the below is working out perfectly fine. The only downside is, that I need to maintain some variables multiple times in different places. The benefit is, that one needs to make changes per site/landscape/environment and not accidentally change the timeserver for all of them.
The layout looks like the below:
# Show the directory tree
$ tree
.
├── inventories
│ ├── dev
│ │ ├── group_vars
│ │ │ ├── control
│ │ │ │ └── vars.yml
│ │ │ └── managed
│ │ │ └── vars.yml
│ │ ├── host_vars
│ │ └── inventory.yml
│ ├── practice
│ │ ├── group_vars
│ │ │ ├── control
│ │ │ │ └── vars.yml
│ │ │ └── managed
│ │ │ └── vars.yml
│ │ ├── host_vars
│ │ └── inventory.yml
│ ├── prod
│ │ ├── group_vars
│ │ │ ├── control
│ │ │ │ └── vars.yml
│ │ │ └── managed
│ │ │ └── vars.yml
│ │ ├── host_vars
│ │ └── inventory.yml
│ └── stage
│ ├── group_vars
│ │ ├── control
│ │ │ └── vars.yml
│ │ └── managed
│ │ └── vars.yml
│ ├── host_vars
│ └── inventory.yml
└── playbook.yml
This can be applied to datacenter sites, too. You just need to change the directory names. For even more complex scenarios, I strongly recommend having a look at Dynamic Inventories (will be the third article of the series).
Variable Precedence
One last word about variable precedence. The more variables you are using and the more complex your playbooks grow, the more you will run into issues where a variable is seemingly not used.
There is a strict order in Ansible how variables can "override" other variables. For our above examples, we are having the following precedence (weakest to strongest).
- Inventory File
- inventory group_vars/*
- inventory host_vars/*
- play vars
So, if you have something in your inventory file, it can be overwritten by values in the group_vars and host_vars, but also variables in the playbook.
A complete list of the variable precedence can be found in the Ansible documentation.
Docs & Links
Ansible provides lots of documentation and best practices building and using your inventory and variables. Please feel free to check out the below links.


Conclusion
Now that we can have variables all over the place, it is a piece of cake to ensure that packages are installed on the correct machines and central network settings are properly adjusted based on our demand.
In the future articles, we will have a look at Dynamic Inventories and Ansible Vault.
Do you know any other cool tips for static inventories? What is your best practice to organize your inventories?